













What is thee difference between utf8_general_ci and utf8mb4_unicode_520_ci in mysql collection
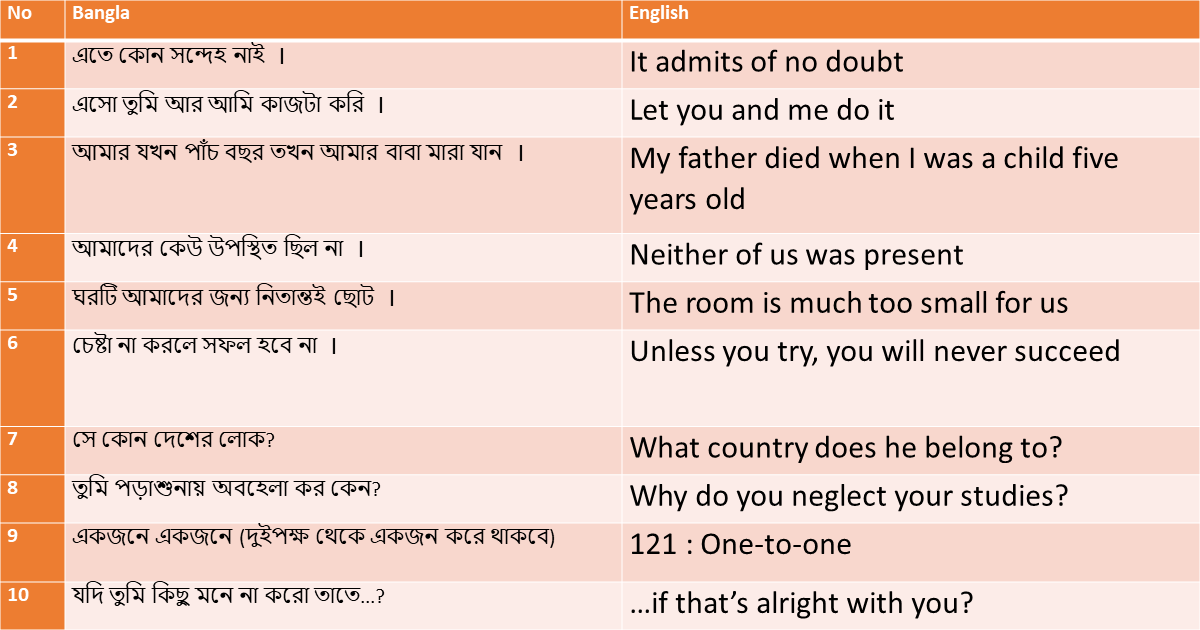
What is thee difference between utf8_general_ci and utf8mb4_unicode_520_ci in mysql collection
Both utf8_general_ci and utf8mb4_unicode_520_ci are collations used in MySQL for the utf8 character set.
utf8_general_ci is a simple collation that does not distinguish between accented and unaccented characters. It treats most variations of a character as equal, which can be useful for case-insensitive comparisons and sorting. However, this can lead to some unexpected behavior, such as treating 'ss' and 'ß' as equivalent.
utf8mb4_unicode_520_ci, on the other hand, is a more complex collation that takes into account the full Unicode character set, including characters that were added in version 5.2 of Unicode. This collation is more accurate in terms of sorting and comparing characters, especially for languages that have many accented or non-Latin characters. It is also capable of handling emojis and other symbols that are not part of the basic utf8 character set.
| Collation Name | Character Set | Description |
|---|---|---|
| utf8_general_ci | utf8 | A simple collation that treats most variations of a character as equal. |
| utf8mb4_unicode_520_ci | utf8mb4 | A more complex collation that takes into account the full Unicode character set. |
Here's a breakdown of the differences between these two collations:
Character Set: utf8_general_ci uses the utf8 character set, while utf8mb4_unicode_520_ci uses the utf8mb4 character set. The utf8 character set can only store up to 3 bytes per character, while utf8mb4 can store up to 4 bytes per character, allowing for a wider range of characters to be stored.
Description: utf8_general_ci is a simple collation that does not distinguish between accented and unaccented characters. It treats most variations of a character as equal, which can be useful for case-insensitive comparisons and sorting. However, this can lead to some unexpected behavior, such as treating 'ss' and 'ß' as equivalent. On the other hand, utf8mb4_unicode_520_ci is a more complex collation that takes into account the full Unicode character set, including characters that were added in version 5.2 of Unicode. This collation is more accurate in terms of sorting and comparing characters, especially for languages that have many accented or non-Latin characters. It is also capable of handling emojis and other symbols that are not part of the basic utf8 character set.
In summary, utf8_general_ci is a simpler collation that can be useful for simple applications and comparisons, while utf8mb4_unicode_520_ci is a more complex and accurate collation that can handle a wider range of characters and symbols.
In summary, utf8_general_ci is a simpler collation that can be useful for simple applications and comparisons, while utf8mb4_unicode_520_ci is a more complex and accurate collation that can handle a wider range of characters and symbols.